
Los avances sofisticados de la inteligencia artificial han dado lugar a Modelos de lenguaje extenso (LLM) como ChatGPT y Bard de Google. Estas entidades pueden generar contenido tan humano que desafía la concepción de la autenticidad.
A medida que los educadores y los creadores de contenido se unen para resaltar el posible uso indebido de los LLM, desde hacer trampa hasta engañar, el software de detección de IA afirma tener el antídoto. Pero, ¿qué tan confiables son estas soluciones de software?
Software de detección de IA no confiable
Para muchos, las herramientas de detección de IA ofrecen un atisbo de esperanza contra la erosión de la verdad. Prometen identificar el artificio, preservando la santidad de la creatividad humana.
Sin embargo, los informáticos de la Universidad de Maryland pusieron a prueba esta afirmación en su búsqueda de la veracidad. ¿Los resultados? Una alarmante llamada de atención para la industria.
Soheil Feizi, profesor asistente de la UMD, reveló las vulnerabilidades de estos detectores de IA y afirmó que no son confiables en escenarios prácticos.
Simplemente parafrasear el contenido generado por LLM a menudo puede engañar a las técnicas de detección utilizadas por Check For AI, Compilatio, Content at Scale, Crossplag, DetectGPT, Go Winston y GPT Zero, por nombrar algunas.
“La precisión incluso del mejor detector que tenemos cae del 100% a la aleatoriedad de un lanzamiento de moneda. Si simplemente parafraseamos algo que fue generado por un LLM, a menudo podemos burlar una variedad de técnicas de detección.”
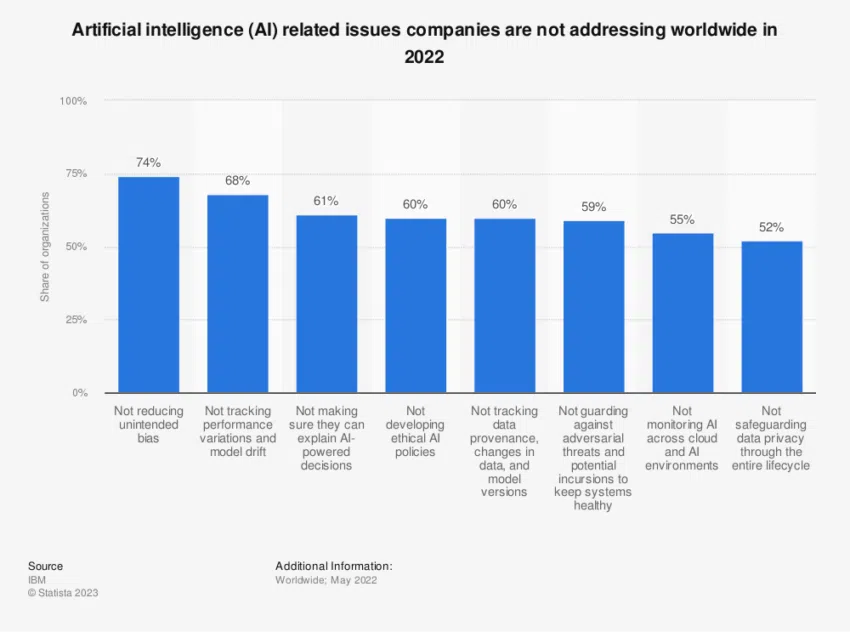
Esta comprensión, argumenta Feizi, subraya la dicotomía poco confiable de los errores de tipo I, donde el texto humano se marca incorrectamente como generado por IA, y los errores de tipo II, cuando el contenido de IA logra pasar desapercibido a través de la red.
Un caso notable apareció en los titulares cuando el software de detección de IA clasificó por error la Constitución de los Estados Unidos como generada por IA. Los errores de tal magnitud no son solo problemas técnicos, sino que pueden dañar la reputación, lo que lleva a graves implicaciones socioéticas.
Feizi aclara aún más la situación, sugiriendo que distinguir entre contenido humano y generado por IA pronto puede ser un desafío debido a la evolución de los LLM.
“Teóricamente, nunca se puede decir de manera confiable que esta oración fue escrita por un humano o algún tipo de IA porque la distribución entre los dos tipos de contenido es muy similar. Es especialmente cierto cuando se piensa en lo sofisticados que se están volviendo los LLM y los atacantes de LLM, como los parafrasistas o la suplantación de identidad.”
Detectar elementos humanos únicos
Sin embargo, como ocurre con cualquier discurso científico, existe una contranarrativa. El profesor asistente de Ciencias de la Computación de la UMD, Furong Huang, tiene una perspectiva más soleada.
Ella postula que con una gran cantidad de datos que significan lo que constituye el contenido humano, la diferenciación entre los dos aún podría ser alcanzable.
A medida que los LLM perfeccionan su imitación alimentándose de vastos repositorios textuales, Huang cree que las herramientas de detección pueden evolucionar si se les da acceso a muestras de aprendizaje más extensas.
El equipo de Huang también se enfoca en un elemento humano único que puede ser la gracia salvadora. La diversidad innata dentro del comportamiento humano, que abarca peculiaridades gramaticales únicas y elecciones de palabras, podría ser la clave.
“Será como una carrera armamentista constante entre la IA generativa y los detectores. Pero esperamos que esta relación dinámica realmente mejore la forma en que abordamos la creación tanto de los LLM generativos como de sus detectores en primer lugar.”
El debate sobre la efectividad de la detección de IA es solo una faceta del debate más amplio de IA. Feizi y Huang coinciden en que prohibir por completo herramientas como ChatGPT no es la solución. Estos LLM tienen un inmenso potencial para sectores como la educación.
En lugar de luchar por un sistema improbable y 100% infalible, el énfasis debe estar en fortalecer los sistemas existentes contra las vulnerabilidades conocidas.
La creciente necesidad de regulación de la IA
Las salvaguardias futuras podrían no basarse únicamente en el análisis textual. Feizi insinúa la integración de herramientas de verificación secundarias, como la autenticación de números de teléfono vinculados a envíos de contenido o análisis de patrones de comportamiento.
Estas capas adicionales podrían mejorar las defensas contra la detección falsa de IA y los sesgos inherentes.
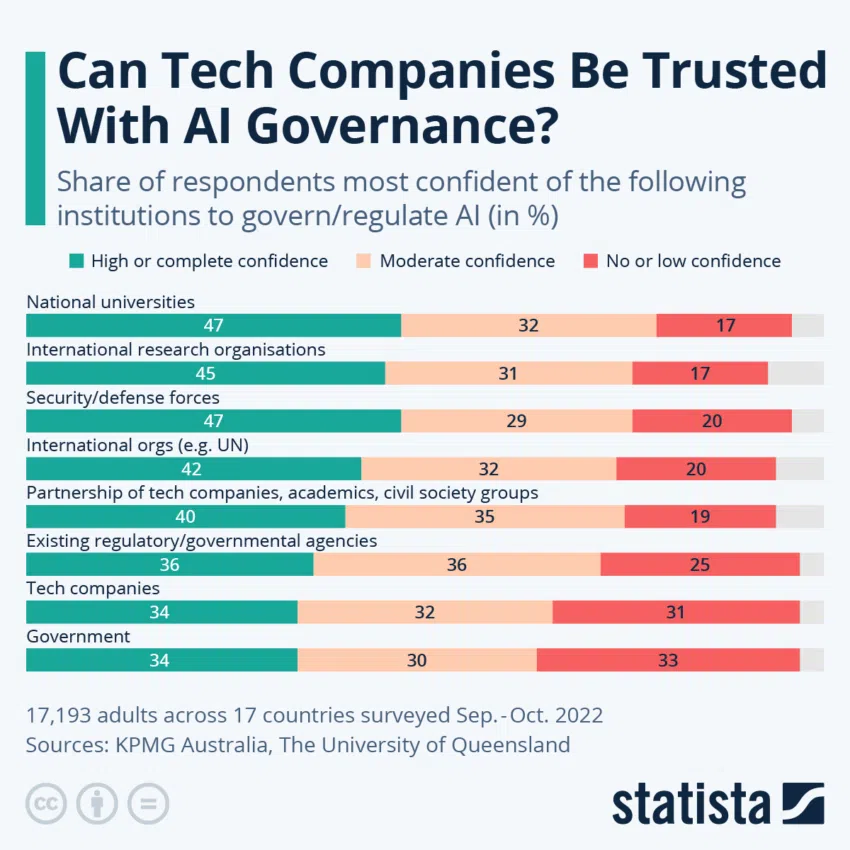
Si bien la IA puede estar cubierta de incertidumbres, Feizi y Huang enfatizan la necesidad de un diálogo abierto sobre la utilización ética de los LLM. Existe un consenso colectivo de que estas herramientas, si se aprovechan de manera responsable, podrían beneficiar significativamente a la sociedad, especialmente en la educación y en la lucha contra la desinformación.
Sin embargo, el viaje por delante no está exento de desafíos. Huang enfatiza la importancia de establecer reglas básicas fundamentales a través de discusiones con los formuladores de políticas.
Un enfoque de arriba hacia abajo, argumenta Huang, es fundamental para garantizar un marco coherente que rija los LLM, ya que la comunidad de investigación busca sin descanso mejores detectores y marcas de agua para frenar el mal uso de la IA.
