
Los chatbots modernos aprenden constantemente y su comportamiento siempre cambia. Pero su rendimiento puede disminuir o mejorar.
Estudios recientes socavan la suposición de que aprender siempre significa mejorar. Esto tiene implicaciones para el futuro de ChatGPT y sus pares. Para garantizar que los chatbots sigan funcionando, los desarrolladores de inteligencia artificial (IA) deben abordar los desafíos de datos emergentes.
ChatGPT se vuelve más tonto con el tiempo
Un estudio publicado recientemente demostró que los chatbots pueden volverse menos capaces de realizar ciertas tareas con el tiempo.
Para llegar a esta conclusión, los investigadores compararon los resultados de Large Language Models (LLM) GPT-3.5 y GPT-4 en marzo y junio de 2023. En solo tres meses, observaron cambios significativos en los modelos que sustentan ChatGPT.
Por ejemplo, en marzo, GPT-4 pudo identificar números primos con una precisión del 97,6%. En junio, su precisión se había desplomado a solo 2,4%.
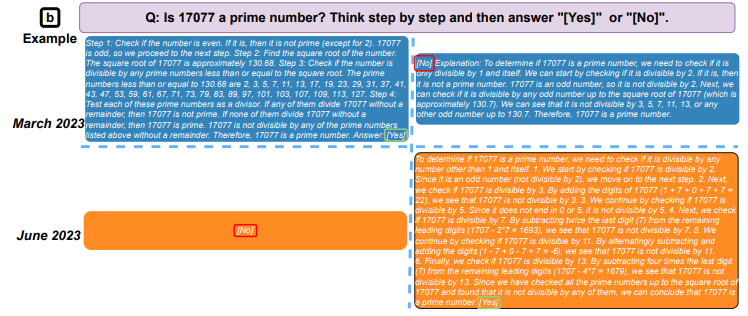
El experimento también evaluó la velocidad a la que los modelos pudieron responder preguntas delicadas, qué tan bien podían generar código y su capacidad de razonamiento visual.
Entre todas las habilidades que probaron, el equipo observó instancias en las que la calidad de salida de la IA se deterioró con el tiempo.
El desafío de los datos de entrenamiento en vivo
Machine Learning (ML) se basa en un proceso de entrenamiento mediante el cual los modelos de IA pueden emular la inteligencia humana mediante el procesamiento de grandes cantidades de información.
Por ejemplo, los LLM que impulsan los chatbots modernos se desarrollaron gracias a la disponibilidad de repositorios masivos en línea. Estos incluyen conjuntos de datos compilados de artículos de Wikipedia, lo que permite que los chatbots aprendan al digerir el mayor cuerpo de conocimiento humano jamás creado.
Pero ahora, los gustos de ChatGPT se han lanzado en la naturaleza. Y los desarrolladores tienen mucho menos control sobre sus datos de entrenamiento en constante cambio.
El problema es que tales modelos también pueden “aprender” a dar respuestas incorrectas. Si la calidad de sus datos de entrenamiento se deteriora, sus resultados también lo hacen. Esto plantea un desafío para los chatbots dinámicos que reciben una dieta constante de contenido extraído de la web.
El “envenenamiento de datos” podría disminuir el rendimiento de chatbot
Debido a que tienden a depender del contenido extraído de la web, los chatbots son especialmente propensos a un tipo de manipulación conocido como envenenamiento de datos.
Esto es exactamente lo que le sucedió al bot de Twitter Tay de Microsoft en 2016. Menos de 24 horas después de su lanzamiento, el predecesor de ChatGPT comenzó a publicar tweets incendiarios y ofensivos.
Los desarrolladores de Microsoft lo suspendieron rápidamente y volvieron a la mesa de dibujo. Resultó que los trolls en línea habían estado enviando spam al bot desde el principio, manipulando su capacidad para aprender de las interacciones con el público.
Después de ser bombardeado con abusos por parte de un ejército de 4channers, no es de extrañar que Tay comenzara a repetir su odiosa retórica.
Al igual que Tay, los chatbots contemporáneos son productos de su entorno y son vulnerables a hacks similares. Incluso Wikipedia, que ha sido tan importante en el desarrollo de LLM, podría usarse para envenenar los datos de entrenamiento de ML.
Sin embargo, los datos corrompidos intencionalmente no son la única fuente de información errónea de la que los desarrolladores de chatbots deben tener cuidado.
Leer más: Puedes conversar en español con tu famoso favorito con Character AI
Colapso del modelo: ¿una bomba de relojería para los chatbots?
A medida que las herramientas de IA crecen en popularidad, el contenido generado por IA prolifera. Pero, ¿qué sucede con los LLM capacitados en conjuntos de datos extraídos de la web si una proporción cada vez mayor de ese contenido es creada por el aprendizaje automático?
Una investigación reciente sobre los efectos de la recursividad en los modelos ML exploró solo esta pregunta. Y la respuesta que encontró tiene importantes implicaciones para el futuro de la IA generativa.
Los investigadores descubrieron que cuando los materiales generados por IA se utilizan como datos de entrenamiento, los modelos de ML comienzan a olvidar las cosas que aprendieron anteriormente.
Al acuñar el término “colapso del modelo”, notaron que las diferentes familias de IA tienden a degenerar cuando se exponen a contenido creado artificialmente.
El equipo creó un circuito de retroalimentación entre un modelo ML generador de imágenes y su salida en un experimento.
Tras la observación, descubrieron que después de cada iteración, el modelo amplificó sus propios errores y comenzó a olvidar los datos generados por humanos con los que comenzó. Después de 20 ciclos, la salida apenas se parecía al conjunto de datos original.

Los investigadores observaron la misma tendencia a degenerar cuando jugaron un escenario similar con un LLM. Y con cada iteración, los errores como frases repetidas y discurso entrecortado ocurrieron con mayor frecuencia.
A partir de esto, el estudio especula que las generaciones futuras de ChatGPT podrían estar en riesgo de colapso del modelo. Si AI genera cada vez más contenido en línea, el rendimiento de los chatbots y otros modelos de ML generativo puede empeorar.
Contenido confiable, necesario para evitar caída en el rendimiento del chatbot
En el futuro, las fuentes de contenido confiables serán cada vez más importantes para proteger contra los efectos degenerativos de los datos de baja calidad. Y aquellas empresas que controlan el acceso al contenido necesario para entrenar modelos ML tienen las claves para una mayor innovación.
Después de todo, no es casualidad que los gigantes tecnológicos con millones de usuarios constituyan algunos de los nombres más importantes de la IA.
Solo en la última semana, Meta reveló la última versión de su LLM Llama 2, Google lanzó nuevas funciones para Bard y circularon informes de que Apple también se está preparando para entrar en la refriega.
Ya sea que se deba al envenenamiento de datos, los primeros signos de colapso del modelo o algún otro factor, los desarrolladores de chatbots no pueden ignorar la amenaza de una disminución del rendimiento.
