
ChatGPT y Gemini de Google han emergido como fuerzas líderes en la carrera por modelos de lenguaje grandes superiores. Es evidente que estas plataformas han transformado la industria de la IA. Sin embargo, cómo adquieren información y gestionan conjuntos de datos ha sido una preocupación ética continua.
BeInCrypto habló con proyectos emergentes de IA en Web3, incluyendo ChainGPT, Space ID, Sapien.io, Vanar Chain, O.XYZ, AR.IO y Kindred, para discutir las preocupaciones contemporáneas sobre derechos de propiedad intelectual, derechos de autor y propiedad. Una conclusión clave fue el potencial de la inteligencia artificial descentralizada (deAI) como una alternativa valiosa.
El auge de los LLMs y el dilema de la adquisición de datos
Desde su creación, los modelos de lenguaje grandes (LLMs) han ganado rápidamente un uso generalizado. En muchos sentidos, plataformas como ChatGPT de OpenAI y Gemini de Google fueron el primer contacto real del público con las capacidades de la inteligencia artificial (IA) y su potencial de uso no exhaustivo.
Sin embargo, estas empresas también han estado bajo escrutinio por sus operaciones. Para seguir siendo competitivos, los modelos de IA necesitan acceso a una gran cantidad de conjuntos de datos. Los LLMs solo pueden generar respuestas similares a las humanas y entender consultas complejas procesando enormes cantidades de texto.
Para lograr esto, gigantes tecnológicos líderes como OpenAI, Google, Meta, Microsoft, Anthropic y Nvidia canalizan en gran medida todos los datos e información disponibles en internet para entrenar sus modelos de IA. Este enfoque ha planteado serias preguntas sobre quién posee la entrada que estas plataformas ingieren y luego regurgitan en forma de salida.
A pesar del potencial disruptivo de la IA, las preocupaciones sobre los derechos de propiedad intelectual han terminado en batallas legales muy disputadas.
¿Están las empresas de IA construyendo imperios?
La rápida adopción de la IA ha planteado preocupaciones sobre la propiedad de los datos, la privacidad y la posible infracción de derechos de autor. Un punto clave de controversia es el uso de material protegido por derechos de autor para entrenar modelos de IA centralizados que las grandes corporaciones controlan exclusivamente:
“Las empresas de IA están construyendo imperios sobre las espaldas de los creadores sin pedir permiso ni compartir las ganancias. Autores, artistas y músicos han pasado años perfeccionando su arte, solo para encontrar su trabajo ingerido por modelos de IA que generan versiones imitadas en segundos”, dijo Jawad Ashraf, CEO de Vanar Chain, a BeInCrypto.
Este problema ha causado de hecho una insatisfacción generalizada. El CEO de Vanar Chain agregó que OpenAI y otros han admitido abiertamente raspar material protegido por derechos de autor, lo que ha provocado demandas y un ajuste de cuentas más amplio sobre la ética de los datos:
“El meollo del asunto es la compensación: las empresas de IA argumentan que raspar datos públicamente disponibles es un juego justo, mientras que los creadores lo ven como un robo a plena luz del día”, afirmó Ashraf.
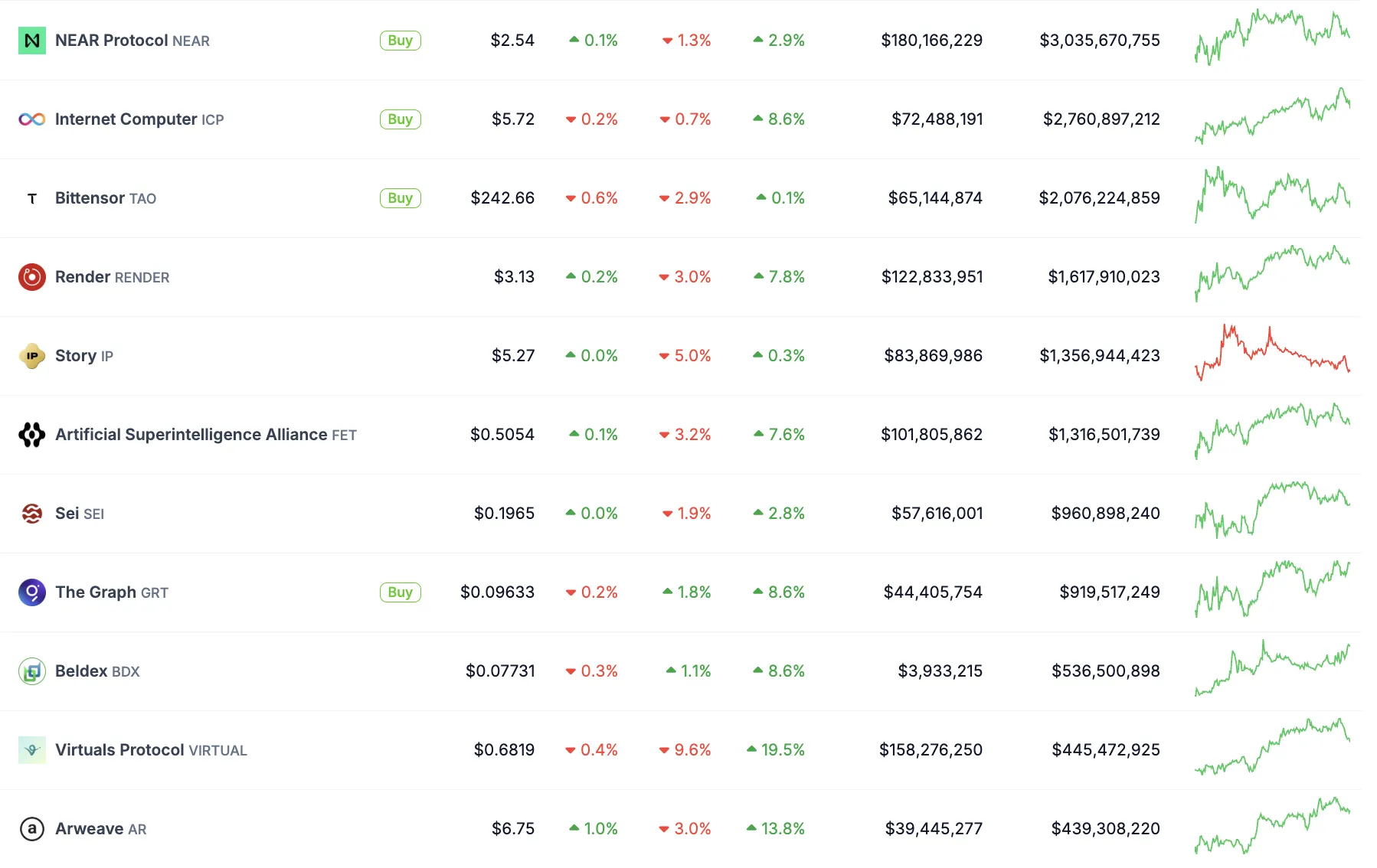
Definiendo los límites del trabajo generado por IA
The New York Times presentó una demanda contra OpenAI y Microsoft en diciembre de 2023, alegando violaciones de derechos de autor y el uso no autorizado de su propiedad intelectual. The Times acusó a Microsoft y OpenAI de crear un modelo de negocio basado en IA:
“Copia y uso ilegal de las obras exclusivamente valiosas de The Times. El periódico también argumentó que estos modelos explotan y, en muchos casos, retienen grandes porciones de la expresión protegida por derechos de autor contenida en esas obras.”
Cuatro meses después, ocho editoras de noticias más que operan en seis estados diferentes de Estados Unidos demandaron a Microsoft y OpenAI por infracción de derechos de autor. The Chicago Tribune, The Denver Post, The Mercury News en California, el New York Daily News, The Orange County Register en California, el Orlando Sentinel.
Asimismo, el Pioneer Press de Minnesota y el Sun Sentinel en Florida – todos alegaron que las dos empresas tecnológicas usaron sus artículos sin autorización en productos de IA y les atribuyeron información inexacta:
“Los tribunales ahora se ven obligados a responder preguntas que no existían hace unos años: ¿El contenido generado por IA constituye una obra derivada? ¿Pueden los titulares de derechos de autor reclamar daños cuando sus datos se utilizan sin consentimiento?” Trevor Koverko, cofundador de Sapien.io, dijo a BeInCrypto.
Además de las organizaciones periodísticas, editoras, autores, músicos y otros creadores de contenido han iniciado acciones legales contra estas empresas tecnológicas por información protegida por derechos de autor.
Batallas legales en diversas industrias
La semana pasada, tres grupos comerciales anunciaron que demandarán a Meta en un tribunal de París, alegando que Meta “utilizó masivamente obras protegidas por derechos de autor sin autorización” para entrenar sus asistentes de chatbot impulsados por IA generativa, que se utilizan en Facebook, Instagram y WhatsApp.
Mientras tanto, las artistas visuales Sarah Andersen, Kelly McKernan y Karla Ortiz demandaron a generadores de arte de IA Stability AI, DeviantArt y Midjourney por usar su trabajo para entrenar sus modelos de IA:
“No hay fin a las preocupaciones cuando se trata del uso no regulado de datos y material creativo por parte de empresas de IA centralizadas. Actualmente, cualquier artista, autor o músico con material públicamente disponible puede ver su trabajo rastreado por algoritmos de IA que aprenden a crear contenido casi idéntico y obtener ganancias de ello mientras el artista no recibe nada”, argumentó Phil Mataras, fundador de AR.IO.
OpenAI y Google argumentan particularmente que si la legislación limita su acceso a material con derechos de autor, Estados Unidos perdería la carrera de IA contra China. Según ellos, las empresas en China operan con menos restricciones regulatorias, dando a sus rivales una ventaja clave.
Estas potencias están presionando agresivamente al gobierno de Estados Unidos para clasificar el entrenamiento de IA en datos con derechos de autor como “uso justo”. Mantienen que el procesamiento de contenido con derechos de autor por parte de la IA resulta en salidas novedosas fundamentalmente diferentes del material fuente.
Sin embargo, a medida que las herramientas de IA generativa producen cada vez más texto, imágenes y voces, muchas industrias están emprendiendo desafíos legales contra estas corporaciones:
“Los creadores de contenido, ya sean autores, músicos o desarrolladores de software, a menudo dicen que su [propiedad intelectual] se está utilizando de maneras que van más allá del uso justo, especialmente cuando los sistemas de IA copian o replican aspectos de su trabajo original”, dijo Ahmad Shadid, fundador y CEO de O.XYZ.
Mientras tanto, en Web3, los actores están presionando por una alternativa al enfoque de las corporaciones tradicionales en el desarrollo de LLM.
DeAI surge como la alternativa Web3
La IA descentralizada (deAI) es un campo emergente en Web3 que explora el uso de la blockchain y la tecnología de libro mayor distribuido para crear sistemas de IA más democráticos y transparentes:
“DeAI, aprovechando la blockchain y la tecnología de libro mayor distribuido, busca abordar las preocupaciones sobre la propiedad de datos y derechos de autor creando sistemas de IA más transparentes. Distribuye el desarrollo y control de modelos de IA a través de una red global, estableciendo modelos más justos para el entrenamiento de IA que respetan los derechos de los creadores de contenido. DeAI también busca proporcionar mecanismos para una compensación equitativa a los creadores cuyo trabajo se utiliza en el entrenamiento de IA, resolviendo potencialmente muchos de los problemas asociados con los modelos de IA centralizados”, explicó Max Giammario, CEO y fundador de Kindred.
Con la creciente prominencia global de la IA, su fusión con la blockchain promete transformar ambos sectores, creando nuevas vías para la innovación e inversión en cripto. En respuesta, los constructores en la industria ya han comenzado a desarrollar proyectos exitosos que fusionan tecnologías de IA y Web3.
A diferencia de las corporaciones que producen modelos de IA centralizados, deAI pretende ser completamente de código abierto. OpenAI ha argumentado previamente que cumple con la doctrina de uso justo de Estados Unidos a pesar de usar material con derechos de autor para entrenar sus modelos de IA.
Además, ChatGPT, su aplicación más popular, es completamente gratuita para usar. Harrison Seletsky, Director de Desarrollo de Negocios en Space ID, destacó una contradicción en el argumento de OpenAI:
“El claro problema ético es que los materiales se están utilizando sin el permiso explícito de sus creadores. Si están protegidos por derechos de autor, se debe otorgar permiso y, típicamente, pagar una tarifa. Pero más allá de eso, incluso si los LLM como ChatGPT usan datos de código abierto, los modelos de OpenAI no son de código abierto. Utilizan material disponible públicamente sin ‘devolver’ completamente a las fuentes de las que extraen.
Hay una pregunta general aquí sobre si la IA debería ser de código abierto. ChatGPT de OpenAI no lo es, mientras que modelos como DeepSeek de China sí lo son, al igual que la IA descentralizada. Desde la perspectiva de la ética y los derechos de propiedad intelectual, esta última es ciertamente una mejor opción”, dijo Seletsky.
El control centralizado de estas potencias tecnológicas también plantea otras preocupaciones sobre la implementación y supervisión de modelos de IA.
Centralizado vs. descentralizado: diferencias operativas
En contraste con la naturaleza impulsada por la comunidad de deAI, los modelos de IA centralizados son construidos por un pequeño número de personas, lo que lleva a posibles sesgos:
“La IA centralizada generalmente opera bajo un único paraguas corporativo, donde las decisiones son impulsadas por un motivo de lucro de arriba hacia abajo. Es esencialmente una caja negra propiedad y gestionada por una entidad. En contraste, DeAI se basa en un enfoque impulsado por la comunidad. La IA está diseñada para analizar los comentarios de la comunidad y optimizar para los intereses colectivos en lugar de solo los corporativos”, explicó Ahmad Shadid, fundador y CEO de O.XYZ.
Mientras tanto, la tecnología blockchain proporciona un camino claro para la monetización:
“Los creadores pueden tokenizar sus activos creativos, como artículos, música o incluso ideas, y establecer sus propios precios. Esto crea un entorno más justo tanto para los creadores como para los usuarios de propiedad intelectual, formando esencialmente un mercado libre para la PI. También hace que la propiedad sea fácil de probar, ya que todo en la blockchain es transparente e inmutable, lo que dificulta mucho más que otros exploten el trabajo de alguien sin alinear adecuadamente los incentivos”, dijo Seletsky a BeInCrypto.
Diferentes constructores de Web3 ya han desarrollado proyectos que descentralizan el contenido utilizado para la IA generativa. Plataformas como Story, Inflectiv y Arweave aprovechan varios aspectos de la tecnología blockchain para asegurar que los conjuntos de datos utilizados para los modelos de IA sean curados éticamente.
Ilan Rakhmanov, fundador de ChainGPT, ve a deAI como una fuerza contraria vital a la IA centralizada. Afirma que abordar las prácticas poco éticas de los monopolios de IA existentes será esencial para cultivar una industria más saludable en el futuro:
“Esto establece un precedente peligroso donde las empresas de IA pueden usar libremente contenido protegido por derechos de autor sin la atribución o pago adecuado. Legalmente, esto invita al escrutinio regulatorio; éticamente, priva a los creadores del control. ChainGPT cree en la atribución y monetización on-chain, asegurando un intercambio de valor justo entre los usuarios de IA, los contribuyentes y los entrenadores de modelos”, dijo Rakhmanov.
Pero, para que DeAI tome el protagonismo, primero debe superar varios obstáculos.
¿Qué obstáculos enfrenta deAI?
Aunque deAI tiene un potencial floreciente, también está en sus etapas iniciales. En ese sentido, empresas como OpenAI y Google tienen la ventaja en cuanto a poder económico e infraestructura. Tienen los medios para manejar los vastos recursos necesarios para adquirir grandes cantidades de datos:
“Las empresas de IA centralizadas tienen acceso a un poder de cómputo masivo, mientras que deAI necesita redes distribuidas eficientes para escalar. Luego está el dato: los modelos centralizados prosperan con conjuntos de datos acumulados, mientras que deAI debe construir canales confiables para obtener, verificar y compensar a los contribuyentes de manera justa”, dijo Koverko a BeInCrypto.
En ese punto, Ahmad Shadid agregó:
“Construir y operar sistemas de IA en registros distribuidos puede ser complicado, especialmente si intentas manejar grandes cantidades de datos a escala. También requiere una supervisión cuidadosa para mantener los procesos de aprendizaje de la IA alineados con la ética y los objetivos de la comunidad.”
Estos gigantes tecnológicos también pueden usar sus recursos y conexiones para presionar fuertemente contra competidores como deAI:
“Podrían hacerlo abogando por regulaciones que favorezcan modelos centralizados, aprovechando su dominio del mercado para limitar la competencia, o controlando recursos clave necesarios para el desarrollo de IA,” dijo Giammario.
Para Ashraf, la probabilidad de que esto suceda debe darse por sentada:
“Cuando todo tu modelo de negocio se basa en acumular datos y monetizarlos en secreto, lo último que quieres es una alternativa abierta y transparente. Espera que los gigantes de la IA presionen contra DeAI, impulsen regulaciones restrictivas y usen sus vastos recursos para desacreditar alternativas descentralizadas. Pero el internet mismo comenzó como un sistema descentralizado antes de que las corporaciones tomaran el control, y la gente está despertando a las desventajas del control centralizado. La lucha por una IA abierta apenas comienza,” anticipó Jawad Ashraf, CEO de Vanar Chain.
Sin embargo, para avanzar en su misión, deAI necesita aumentar su conciencia pública, llegando tanto a los usuarios de Web3 como a aquellos fuera del espacio.
Reduciendo la brecha de conocimiento
Cuando se le preguntó sobre los principales obstáculos que enfrenta actualmente deAI, Seletsky de Space ID dijo que las personas deben ser conscientes del problema de la infracción de derechos de autor en los modelos de IA para resolverlo:
“El principal obstáculo es la falta de educación. La mayoría de los usuarios no saben de dónde provienen los datos, cómo se analizan y quién los controla. Muchos ni siquiera se dan cuenta de que la IA tiene sesgos, al igual que los humanos. Es necesario educar a la persona promedio sobre esto antes de que puedan entender las ventajas de los modelos de IA descentralizados,” dijo.
Una vez que el público entienda los problemas de derechos de autor dentro de los modelos de IA centralizados, los defensores de deAI deben demostrar activamente los méritos de deAI como una alternativa sólida. Sin embargo, a pesar del aumento de la conciencia, deAI aún enfrenta desafíos de adopción:
“La adopción es otro desafío. Las empresas están acostumbradas a soluciones de IA llave en mano, y deAI necesita igualar ese nivel de accesibilidad mientras demuestra sus ventajas en seguridad, transparencia e innovación,” dijo Koverko.
Claridad regulatoria y confianza pública
Con los desafíos de educación y accesibilidad abordados, el camino hacia una adopción más amplia de deAI depende de establecer claridad regulatoria y construir confianza pública. Trevor Koverko, cofundador de Sapien.io, también agregó que deAI necesita claridad regulatoria acompañante para alcanzar estos objetivos:
“Sin marcos claros, los proyectos deAI corren el riesgo de ser marginados por la incertidumbre legal mientras los actores centralizados presionan por políticas que beneficien su dominio. Superar estos desafíos significa refinar nuestra tecnología, demostrar valor en el mundo real y construir un movimiento que impulse una IA abierta y democratizada,” afirmó.
Shadid coincidió con la necesidad de un mayor respaldo institucional, agregando que debería ir acompañado de la construcción de una mayor confianza pública:
“La transparencia puede ser inquietante si has pasado décadas perfeccionando métodos propietarios, por lo que DeAI debe demostrar su superioridad en términos de confianza e innovación. Otro obstáculo es construir suficiente confianza del usuario y claridad regulatoria para que las personas, e incluso los gobiernos, se sientan cómodos con cómo se manejan los datos. La mejor manera de ganar tracción es demostrar casos de uso en el mundo real donde la IA descentralizada claramente supere a sus contrapartes centralizadas o al menos demuestre que puede igualarlas en velocidad, costo y calidad mientras es mucho más abierta y justa,” explicó Ahmad Shadid.
En última instancia, las preocupaciones sobre derechos de autor en torno a los modelos de IA requieren un cambio de paradigma, enfocándose en respetar la propiedad intelectual y promover un ecosistema de IA más democrático, independientemente del impacto final de deAI.
