
Nuestro sitio, BeInCrypto, se incluyó en un conjunto de datos para entrenar y mejorar la IA, como ChatGPT, según un análisis reciente.
BeInCrypto se ha incluido en un gran conjunto de datos para entrenar IA llamado C4.
Recientemente, el Washington Post y el Instituto Allen para la IA estudiaron el conjunto de datos C4 de Google para determinar qué sitios estaban alimentando las herramientas de IA.
Muchos modelos de lenguaje grandes han utilizado C4 (que significa Colossal Clean Crawled Corpus) como herramienta de instrucción.
Sin embargo, ChatGPT de Open AI no utiliza este conjunto de datos.
Los modelos de lenguaje grande como C4, y el empleado por ChatGPT, “raspan” Internet en busca de contenido para incluir en su modelo.
La inmensidad del conjunto de datos permite que la IA imite el habla humana.
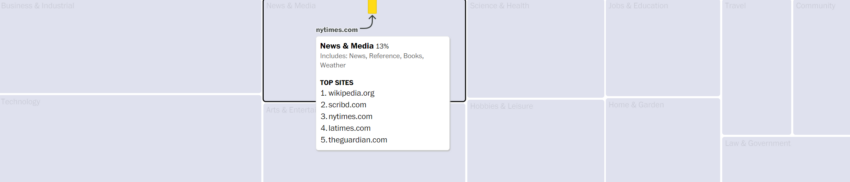
El periódico clasificó los sitios web de C4 utilizando datos de la empresa de análisis web Similarweb.
Luego, clasificaron los 10 millones de sitios web principales por la cantidad de “tokens” que contribuyeron.
Los tokens se refieren a fragmentos cortos de texto utilizados para dar sentido a datos no estructurados, que generalmente consisten en una palabra o una frase.
Los tres mayores contribuyentes al conjunto de datos fueron patents.google.com, wikipedia.org y scribd.com, una biblioteca digital basada en suscripción.
Y las organizaciones de noticias dominaron los primeros puestos, con The Guardian, New York Times, Forbes, LA Times y Huffington Post entre los 10 primeros.
Datos para C4 First Scraped en 2019
Otros sitios web que se destacan en gran medida incluyen Instructables, una plataforma en línea para compartir instrucciones y procedimientos de bricolaje.
Y los investigadores también encontraron al menos otros 27 sitios identificados por el gobierno de Estados Unidos como mercados para la piratería y las falsificaciones.
C4 comenzó como un raspado único de la organización sin fines de lucro CommonCrawl en 2019.
Le dijeron al Washington Post que no intenta evitar el material con licencia o con derechos de autor.
Aunque sí trata de priorizar sitios web de alta calidad y confianza. Además, sus datos son de uso y análisis gratuitos.
A medida que la tecnología de IA continúa amenazando a varias industrias, el raspado de contenido para modelos de lenguajes grandes se ha vuelto cada vez más controvertido, particularmente en los sectores con mayor riesgo de IA.
Las empresas de formación en IA no compensan a los creadores de contenido por el uso de su trabajo.
Además, los artistas han atacado recientemente las herramientas de imagen de IA Midjourney y Stable Diffusion con una demanda por derechos de autor.
Y la demanda afirma que las herramientas de arte generativo de IA violan la ley de derechos de autor al copiar el trabajo de los artistas sin su consentimiento.
Los expertos esperan que se tomen más medidas contra el raspado de Internet.
